Get Full Government Meeting Transcripts, Videos, & Alerts Forever!
University of Washington statistician urges shift from profile probabilities to match probabilities in forensic DNA reporting
Summary
Dr. Bruce Weir presented empirical and theoretical evidence that multiplying single-locus genotype frequencies can understate match probabilities as more loci are used, and he recommended the likelihood-ratio/match-probability framework and larger theta values to avoid overstating evidence.
Dr. Bruce Weir, a professor of biostatistics and director of the Institute of Public Health Genetics at the University of Washington, said forensic DNA reporting should emphasize match probabilities and likelihood ratios rather than product-based "profile probabilities." He told the American Academy of Forensic Sciences symposium that multiplying single-locus genotype frequencies as loci accumulate produces astronomically small numbers that are hard to interpret and can misstate evidentiary strength.
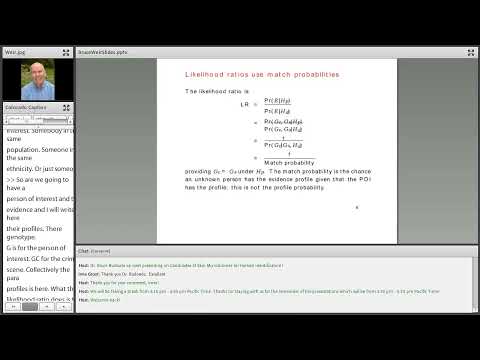
"I want to put match back into match probabilities," Weir said, arguing that a proper match probability compares a pair of profiles — the evidence profile and a person-of-interest profile — under competing propositions. He said the commonly reported random match probability, defined in a NIST example as the product over loci of genotype frequency estimates, rests on independence assumptions…
Already have an account? Log in
Subscribe to keep reading
Unlock the rest of this article — and every article on Citizen Portal.
- Unlimited articles
- AI-powered breakdowns of topics, speakers, decisions, and budgets
- Instant alerts when your location has a new meeting
- Follow topics and more locations
- 1,000 AI Insights / month, plus AI Chat