Get Full Government Meeting Transcripts, Videos, & Alerts Forever!
Eye‑tracking study finds visual context shapes how latent‑print examiners search and decide
Summary
A research team led by Austin Hicklin presented eye‑tracking evidence that visual context (latent vs. exemplar vs. cropped views) changes where examiners look, how long they search and how quickly they reach a decision; the study used about 121 practicing examiners and produced two forthcoming papers.
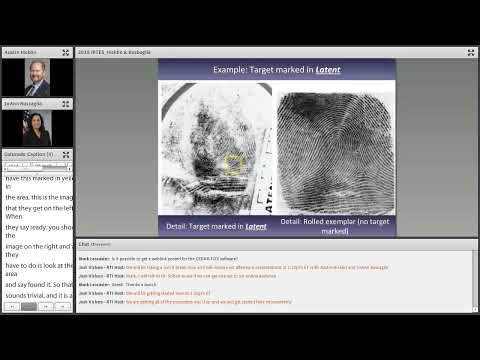
Austin Hicklin, senior fellow at Noblis, presented results from an eye‑tracking study of latent‑print examiners, saying the data reveal how examiners search fingerprint images and why they sometimes reach different conclusions. "So we're talking about eye tracking for latent print examinations," Hicklin told attendees, framing the work as a complement to previous accuracy studies.
Hicklin said the project—co‑authored by Joanne Buscaglia (research chemist, FBI Laboratory), Brad Olery (Noblis), Tony Roberts (FBI Laboratory) and Tom Busey (Indiana University)—used head‑stabilized eye tracking sampling about 1,000 times per second and a registration process that maps gaze to image points with an accuracy on the order of a ridge. "It provides us more…
Already have an account? Log in
Subscribe to keep reading
Unlock the rest of this article — and every article on Citizen Portal.
- Unlimited articles
- AI-powered breakdowns of topics, speakers, decisions, and budgets
- Instant alerts when your location has a new meeting
- Follow topics and more locations
- 1,000 AI Insights / month, plus AI Chat