Method note: FlashID, FBI 100 and sample design underpin random-match estimates
Get AI-powered insights, summaries, and transcripts
Subscribe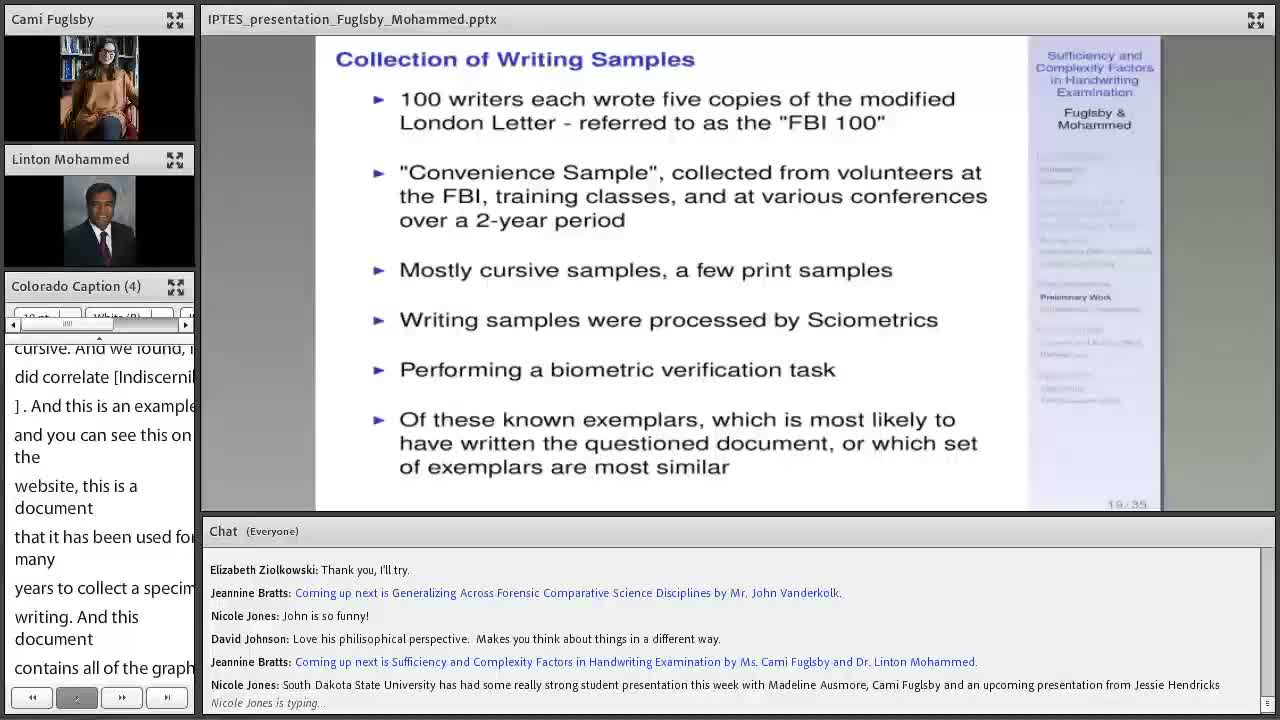
Summary
Presenters described the sample design ("FBI 100" convenience sample, Alabama samples), FlashID/Syometrics processing, and use of Pearson chi-square statistics to estimate error rates, cautioning short words and printing-versus-cursive differences limit some automated approaches.
Presenters described the datasets and computational methods used to estimate random match and non-match probabilities. The study used a convenience sample called the "FBI 100": 100 volunteer writers who each provided five copies of a modified London-letter specimen processed by Syometrics/FlashID. The team also used Alabama-word samples and noted that short words such as "Alabama" pose challenges for some algorithms because they contain few characters, requiring a specialized ("boutique") algorithm in that case.
Methodologically, the presenters applied uncorrected and corrected Pearson chi-square statistics to cross-classified FlashID outputs and treated classification decisions with a threshold (tau) to estimate error rates. They explained random non-match probability estimation by sampling two documents from the same writer and calculating how often similarity scores fall below tau; random match probability was estimated similarly from pairs of different writers. The presenters noted the estimator has the form of a degree-2 U-statistic and is approximately normal by asymptotic arguments.
They also discussed stylistic differences in modern samples: more printing than cursive among some participants (because cursive is less commonly taught), and that examiners should compare like-with-like (uppercase with uppercase, script with script). Presenters flagged the need for longer exemplars and for further validation of FlashID's full feature set in future work.