Lifetime Citizen Portal Access — AI Briefings, Alerts & Unlimited Follows
Researcher finds high variability among latent fingerprint examiners, outlines a multi-scale tool and new NIJ-funded palm study
Loading...
Summary
Heidi Eldridge presented preliminary results showing substantial variability among latent fingerprint examiners and described a prototype multi-scale assessment tool; she announced a new NIJ grant to replicate black-box methods for palm comparisons and called for partners to validate the tool in casework.
Heidi Eldridge, a research forensic scientist at RTI International and a latent fingerprint examiner, presented preliminary findings from a study she said was designed to probe how examiners reach suitability and identification decisions. "Fingerprint examiners are variable," Eldridge told attendees, describing variability both in final source/non-source calls and in suitability determinations during analysis.
Eldridge said conventional explanations that rely on a simple minutiae-count threshold (often described as an operational tipping point near seven or eight minutiae) do not fully explain what practitioners decide. She cited the field's longstanding position that "no scientific basis exists for requiring a predetermined minimum number of features to establish a positive identification" and pointed to examples where examiners marked many minutiae yet called an image "no value," or marked few minutiae and called it "value."
To better capture what a latent mark can reliably be used for, Eldridge proposed evaluating marks on multiple, separate scales rather than a single yes/no value. She outlined four axes—value (what the mark can support: identification, exclusion, comparison), complexity, a quality threshold discussed in the talk as "APHis" quality, and a difficulty tier—and described the project's goal of producing a tool, automated or hybrid, that rates a mark along these scales.
The study used 100 fingermark images from prior casework; each participant received a randomized set of 30 images to annotate using a web interface developed at the University of Lausanne. Participants were asked to annotate the features they used to reach decisions, not simply everything they could see. Eldridge reported 105 participants completed all 30 trials and 11 completed some trials; each image was seen by between 26 and 41 examiners, yielding more than 3,000 completed analyses.
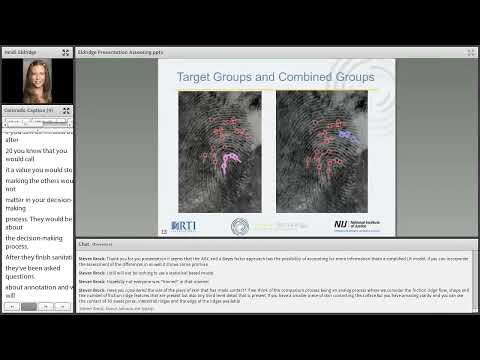
Using what she identified as the PIANO web interface, Eldridge demonstrated annotation tools—target-group and combined-group markers, incipient-ridge lines and pore dots—designed to capture which features examiners relied on. Preliminary analyses showed minutiae count correlates with value calls at the extremes but does not reliably predict complexity. Combining variables (for example, distortion and clarity) produced clearer groupings for some images but also left notable outliers; Eldridge emphasized the high inter-examiner variance shown in the data and said the variance was large even when error bars represented one-tenth of a standard deviation.
"We could force this into a model doing all kinds of averaging... a lot of people won't be happy with that," she said, describing three community options: rely on averaged consensus models, remove the human via automation, or pursue a hybrid approach that leverages examiner observations plus objective measures. Eldridge said the five characteristics that consistently ranked highest across analyses were number of minutiae, number of minutiae the examiner was sure about, clarity/quality, rarity or discriminability of features, and pattern type.
As next steps, Eldridge said the team will incorporate objective clarity and rarity metrics into the model, validate the approach with laboratory partners in casework, and conduct more analyses to define appropriate ground truth. She also announced a new grant from the National Institute of Justice: "I have a new NIJ grant that I was just awarded where we will be basically replicating the good work of FBI Noblis in their well known black box study, but we'll be focusing exclusively on palms instead of fingerprints to try to establish a baseline for palm comparisons," she said, and asked conference attendees to expect invitations to participate.
In a question from the online audience about whether the size of the contacting skin area was considered, Eldridge said the initial 100-image set mostly contained similarly sized impressions and that size was not explicitly factored into this first analysis, but she acknowledged it as a worthwhile variable to examine in future work.
Eldridge characterized the findings as preliminary and called for further validation: the planned validations and laboratory trials, she said, will determine whether a hybrid tool can produce repeatable, useful results in routine casework.